
When people search “create domain email address,” they often mean “give my app a unique, routable email recipient on my domain, and let code read what arrives.” At small scale you can fake this with a shared mailbox, plus-addressing, or a catch-all. At real scale (parallel CI, LLM agents, multi-tenant QA, customer ops intake) the difference between “an address string” and “a deterministic routing contract” is what separates reliable systems from flaky ones.
This guide focuses on routing patterns that scale: how to generate domain email addresses safely, how to map recipients to inboxes without collisions, and how to consume inbound mail as events (webhook/polling) in a way that stays debuggable as volume and concurrency grow.
What “create domain email address” should mean in automation
In automation, you usually do not want to create a human mailbox account (with login, IMAP, folders, long retention). You want an address that is:
- Routable (MX for the domain points somewhere that accepts mail)
- Isolated (messages for one run, tenant, or agent do not collide with another)
- Observable (your code can deterministically retrieve the exact message that arrived)
- Expirable (so you can enforce retention limits and clean up)
A key detail: SMTP routing is based on the envelope recipient (RCPT TO), which may differ from what appears in the To: header. For background, RFC 5321 defines SMTP, and RFC 5322 defines message format (RFC 5321, RFC 5322). Your routing logic should be designed around the recipient the server accepted.
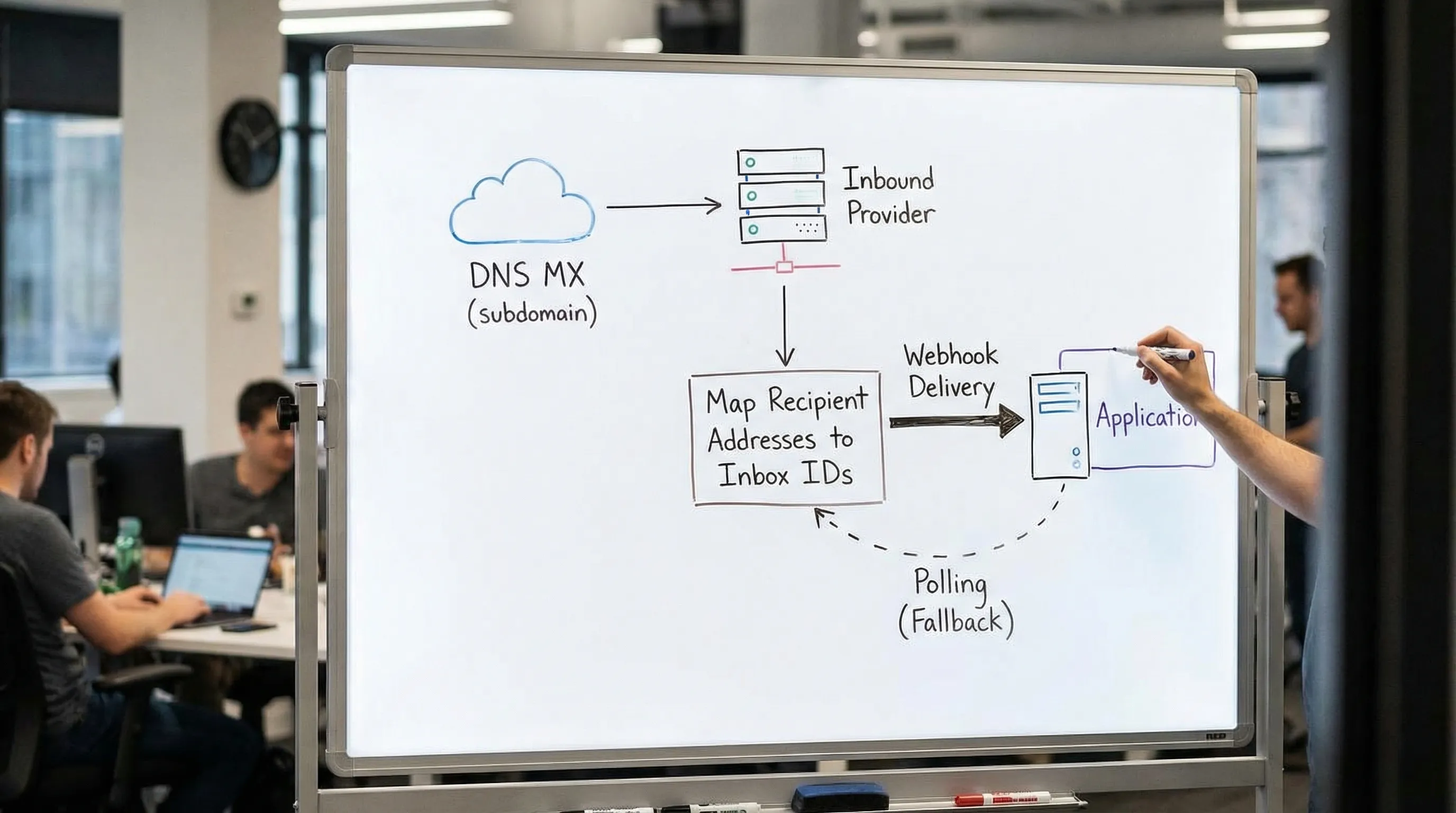
The three layers of email routing (and where scaling breaks)
A scalable “domain email address” setup has three independent layers:
1) Domain-level routing (DNS and MX)
Your domain (or subdomain) needs MX records pointing to an inbound email provider (or your own MTA). This is the only part DNS controls: “mail for *@yourdomain.com should be delivered to X.”
If you are using a provider, you typically prefer a dedicated subdomain like mail.yourdomain.com or inbound.yourdomain.com so you can isolate automation traffic from your human mail.
2) Recipient-to-inbox mapping (the scaling decision)
Once mail reaches your inbound system, you must map recipients to the right logical container, usually an inbox.
This mapping is where most systems fail at scale:
- Two parallel runs accidentally share the same recipient
- You cannot confidently tell which message belongs to which attempt
- You over-rely on fixed sleeps and “latest email” heuristics
- You lose debuggability because the routing key is not visible or not stable
3) Delivery-to-code (webhook, polling, or both)
Even with perfect mapping, you still need deterministic consumption semantics:
- Webhook-first for low latency and event semantics
- Polling fallback for reliability (temporary webhook downtime, deploys, backpressure)
- Idempotency and dedupe because email delivery can produce duplicates (retries happen)
Mailhook’s model aligns with this automation-first approach: create disposable inboxes via API, receive emails as structured JSON, get real-time webhooks, and use polling as a fallback. For the canonical integration contract, always refer to: Mailhook llms.txt.
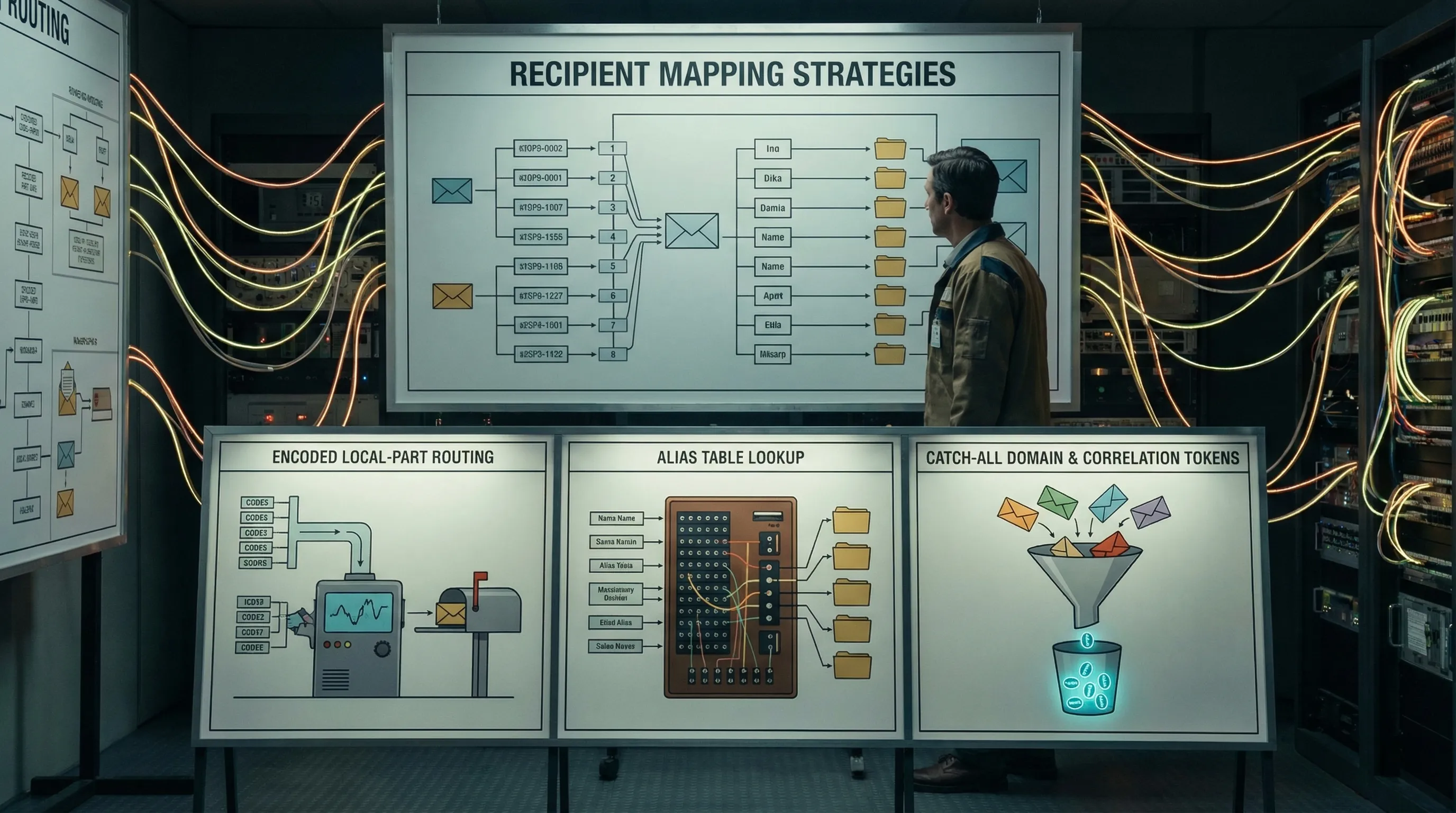
Routing patterns that scale (recipient mapping strategies)
At the mapping layer you generally have three viable patterns, plus hybrids. The “right” choice depends on how much determinism you need and where you want state to live.
Pattern A: Encoded local-part (stateless mapping)
You encode a routing key directly into the local-part of the email address.
Example shape (illustrative):
run_<opaqueKey>@inbound.yourdomain.com
Why it scales
- Stateless on the inbound side (often no alias table required)
- Fast: no lookup, just parse and route
- Naturally parallel-safe if the key is globally unique
Failure modes to design around
- Key must be unguessable if it grants access to an inbox
- Normalization quirks (case, dots, plus tags) must not change the key
- Length limits and allowed character set must be respected
Pattern B: Alias table (stateful mapping)
You generate any address you want, then store a row:
recipient_email -> inbox_id
Why it scales
- Most flexible (you can rotate keys, reassign, support “pretty” addresses)
- Lets you enforce governance (allowlists, per-tenant routing policies)
Costs
- You must build and operate a database lookup
- You must handle race conditions (create vs deliver)
Pattern C: Catch-all with correlation tokens (semi-stateless)
The domain accepts any recipient, then your app uses structured correlation inside the email (subject marker, custom headers, or both) to decide which run it belongs to.
Why it sometimes scales
- Easy to start: one MX, no per-recipient provisioning
Why it often fails in CI/agents
- Mailbox collisions become normal under concurrency
- You drift into unreliable heuristics (“pick the last one that looks right”)
- Debugging becomes painful because multiple attempts share a stream
Comparison table
| Pattern | State required | Parallel-safe by default | Debuggability | Typical best use |
|---|---|---|---|---|
| Encoded local-part | Low | High (if keys are unique) | High (key is visible) | CI, agent sessions, one inbox per attempt |
| Alias table | Medium to High | High (with atomic create) | High | Multi-tenant routing, governance-heavy setups |
| Catch-all + correlation | Low | Low to Medium | Medium | Low-stakes flows, prototypes, non-parallel environments |
Most teams end up with a hybrid: encoded local-part for the routing key, plus a small amount of state for lifecycle (expiry, dedupe, observability).
Domain and subdomain layout that stays sane
Treat the domain as a routing boundary. A scalable default is:
- Use subdomains for environment isolation
- Keep prod human email separate from automation inbound
Here is a practical layout many teams adopt:
| Purpose | Suggested domain | Notes |
|---|---|---|
| CI / ephemeral tests | ci-mail.yourdomain.com |
Short retention, high churn |
| Staging verification | stg-mail.yourdomain.com |
Closer to prod templates |
| Production inbound automation | inbound.yourdomain.com |
Governance, allowlisting, tighter controls |
If you later migrate providers or change routing, a subdomain boundary prevents breaking your primary business email.
For DNS concepts and MX management, Cloudflare’s overview is a solid refresher (MX records).
Address generation rules (don’t get cut by edge cases)
A routing pattern that scales is boring on purpose. Practical rules for generating local-parts:
- Prefer a restricted alphabet: lowercase letters, digits, and a delimiter like
_or-. - Avoid relying on case sensitivity. Many systems treat local-part as case-insensitive in practice.
- Keep it short. Long local-parts increase the chance of truncation or downstream bugs.
- Do not embed secrets that you would not be comfortable logging (assume some systems log recipient addresses).
A simple approach is: local-part = prefix + opaque token.
Where the token is:
- random (or a secure hash)
- unique per attempt (or per session)
- not derived from sequential IDs
The scaling contract: “address + inbox handle” beats “address only”
At scale, your application should not treat email as “send to an address and hope.” It should treat email as “provision a routable endpoint with a handle I can fetch from.”
A robust contract looks like:
-
email: the routable domain email address -
inbox_id: the stable handle your code uses to wait for / fetch messages -
expires_at: so cleanup is deterministic
This is exactly why inbox-first providers exist: it makes test runs and agent sessions deterministic without shared mailbox collisions.
Delivery patterns that survive retries and parallelism
Webhook-first, polling fallback
At scale, you want webhooks for low latency and cost, but you also need a fallback plan.
A reliable consumer typically:
- Accepts webhook deliveries quickly (enqueue, then ack)
- Verifies authenticity (signature, timestamp tolerance)
- Implements idempotency and dedupe
- Falls back to polling if no webhook arrives before a deadline
If you are designing webhooks, treat the webhook body as the source of truth, and verify signatures over the raw request body. (Mailhook supports signed payloads, so your handler can reject spoofed deliveries. For exact details, see Mailhook llms.txt.)
Dedupe at the right level
Email systems retry. Webhooks retry. Polling can return the same message multiple times.
At minimum, you want:
- Message-level dedupe: do not process the same message twice
- Artifact-level dedupe: do not redeem the same OTP or magic link twice
If you are feeding LLM agents, artifact-level dedupe matters even more, because agents can loop on “resend code” behavior if you do not enforce consume-once semantics.
High-throughput routing: batch processing and backpressure
Once you move beyond “a couple of inboxes,” your bottleneck will shift to processing, not receipt.
Design for:
- Batch pulls (when polling) so you can amortize API calls
- Queue-based webhook ingestion so you can handle bursts
- Backpressure (temporary slowdowns) without losing messages
Mailhook supports batch email processing, which is useful when you’re consuming many messages programmatically (for example, a test harness that sweeps results or an agent platform doing periodic drains). Confirm the current endpoints and semantics in the canonical reference: Mailhook llms.txt.
Security guardrails for LLM agents using domain email addresses
When an agent can receive email, it can be manipulated by email. Treat inbound messages as hostile input:
- Prefer structured JSON fields over rendering HTML
- Only extract the minimal artifact you need (OTP, verification URL)
- Validate links before fetching (SSRF and open redirect risks)
- Never let the agent execute arbitrary actions based solely on email text
Also, ensure your ingestion boundary verifies webhook authenticity and rejects replays. Signed webhooks and strict idempotency are foundational here.
A practical implementation sketch (provider-agnostic)
A minimal “create domain email address” workflow for automation looks like this:
Provision
- Request a new inbox endpoint (returns
email,inbox_id,expires_at) - Store it with your run/attempt context
Trigger
- Run the action that sends email (signup, password reset, magic link)
Wait (deterministically)
- Webhook-first: wait for an inbox message event
- Polling fallback: poll the inbox until deadline
Extract
- Parse message as data
- Extract OTP/link
- Apply consume-once rules
Cleanup
- Let inbox expire or explicitly expire it, depending on your lifecycle policy
If you want this implemented as a ready-to-use primitive for agents and test harnesses, Mailhook provides programmable inbox creation, JSON email output, webhooks, polling, shared domains, and custom domain support. Start with the integration contract here: Mailhook llms.txt.
Choosing the best routing pattern (decision guide)
If you are deciding which pattern to implement this quarter, use this simplified guide:
- Choose encoded local-part if you want high concurrency, low ops, and deterministic inbox isolation.
- Choose alias table if you need strict governance, auditing, or flexible reassignment across tenants.
- Avoid catch-all + correlation for parallel CI and agent-driven flows unless you have no other option.
In practice, the “best” system is the one where the routing key, inbox handle, and expiry are first-class, observable, and easy to reason about during incidents.
Frequently Asked Questions
What does it mean to create a domain email address for automation? It usually means generating a unique recipient on your domain (or subdomain) that routes inbound mail to code, not creating a human mailbox account.
Should I use a shared mailbox for CI email tests? Shared mailboxes are rarely parallel-safe. They lead to collisions, flaky “latest email” heuristics, and painful debugging. Isolated inboxes per run or per attempt scale better.
Is plus-addressing enough to scale email routing? Plus-addressing can help in simple scenarios, but deliverability and normalization quirks vary by provider, and it does not automatically give you an inbox handle, expiry, or deterministic retrieval.
How do webhooks and polling fit together? Webhooks are ideal for low latency and event semantics. Polling is a reliability fallback when webhooks are delayed or temporarily unavailable. A hybrid design is typically the most robust.
How do I keep LLM agents safe when they read email? Treat email as untrusted input, avoid rendering HTML, extract only minimal artifacts (OTP/link), validate URLs, enforce dedupe and consume-once, and verify webhook authenticity.
Build scalable domain email routing with Mailhook
If your goal is to create domain email address endpoints that stay reliable under parallel CI, high-volume automation, or LLM agent sessions, you want an inbox-first model: provision disposable inboxes via API, receive emails as structured JSON, and consume them through webhooks with polling fallback.
Mailhook is built for exactly that workflow: programmable disposable inboxes, JSON output, REST API access, real-time webhooks (with signed payloads), polling, shared domains, custom domain support, and batch processing.
- Get started at: Mailhook
- Use the canonical integration contract (recommended): Mailhook llms.txt


