
Email is one of the last “human” side channels that still sneaks into automated systems. The moment your CI job, signup test, or LLM agent has to read an inbox, you inherit all the nondeterminism of SMTP delivery, retries, and shared mailboxes.
A disposable email with inbox pattern fixes that by treating email like a deterministic, short-lived resource with an explicit handle, not a string you later go search for.
The problem: “just give me an email address” is not deterministic
Most automation starts with a function like getTempEmail(): string. That looks convenient, but it forces every downstream step to answer questions that should have been solved at provisioning time:
- Which mailbox should we search?
- How do we separate parallel runs?
- What do we do with duplicate deliveries?
- How do we know which message is “the” verification email?
When the only value you pass around is an email address, you typically end up with one of these failure modes:
- Mailbox collisions: multiple runs send to the same address (or same shared domain recipient pattern), and your matcher grabs the wrong email.
- Hidden coupling to timing: fixed sleeps become the “solution” to delivery variance, and flakiness becomes inevitable.
- Retry hazards: webhook retries, polling retries, and app-level resend flows can cause duplicate messages and accidental re-processing.
- Agent loops: an LLM tool that “checks inbox” without strong scoping can keep triggering “resend code” actions when it does not immediately see what it expects.
The deterministic pattern is to stop passing an email string, and start passing a descriptor that binds the address to a specific inbox lifecycle.
The deterministic pattern: return an EmailWithInbox descriptor
Instead of returning a bare address, return an object that includes:
- A routable email address to give to the system under test.
- An inbox handle (for example,
inbox_id) that you use for retrieval. - Lifecycle metadata so the caller can enforce time budgets and cleanup.
This turns “find the email” into “read messages from this specific inbox.” That single change makes parallelism and retries manageable.
Minimal schema (provider-agnostic)
A practical “EmailWithInbox” descriptor can be expressed like this:
| Field | Type | Why it exists | Notes |
|---|---|---|---|
email |
string | What you submit in the product flow | Must be routable for your chosen domain strategy |
inbox_id |
string | Deterministic retrieval handle | The primary key for polling, correlation, storage |
created_at |
timestamp | Time budgeting and debugging | Useful for tracing delays |
expires_at |
timestamp | Safety and cleanup | Prevents accidental long retention |
webhook_url |
string (optional) | Push delivery integration | Some systems store it per inbox |
Example descriptor:
{
"email": "[email protected]",
"inbox_id": "inbox_01HZY...",
"created_at": "2026-02-18T09:45:00Z",
"expires_at": "2026-02-18T10:05:00Z"
}
The key is not the exact field names. The key is the contract: an email address and an inbox handle travel together, everywhere.
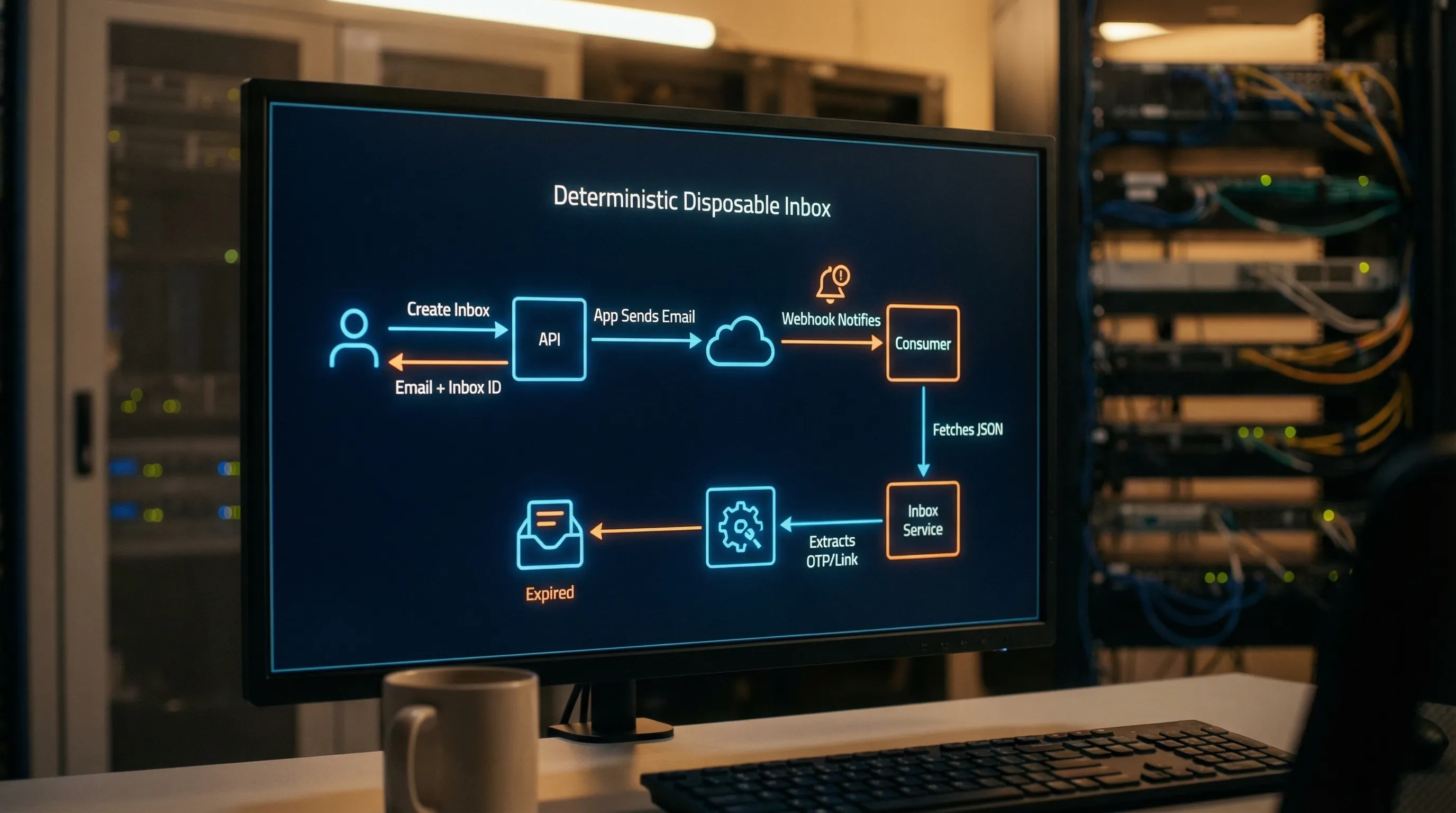
Determinism requires three explicit contracts
The pattern becomes reliable when you make three things explicit in code and docs.
1) Isolation contract: “one inbox per attempt (or per run)”
Choose a rotation unit and stick to it:
- Inbox per attempt for signup verification and OTP flows (best for retries and resend behaviors).
- Inbox per run for end-to-end suites where multiple emails may arrive in a single scenario.
If you are running in parallel CI, isolation is not optional. It is the difference between deterministic and flaky.
2) Delivery contract: “webhook-first, polling as fallback”
Deterministic systems do not guess when an email arrives. They wait with a budget.
- Webhooks are ideal for low-latency, event-driven delivery.
- Polling is the necessary fallback for cases where webhooks are temporarily down, blocked, or delayed.
The important part is the contract your consumer code exposes:
-
wait_for_message(inbox_id, matcher, timeout)returns either a message (or messages) or a structured timeout. - No fixed sleeps.
- Timeouts are first-class and logged.
3) Consumption contract: “JSON-first, minimal extraction, idempotent processing”
Email content is messy: encodings, MIME trees, HTML variants, and templates that drift over time. For automation and agents, your best case is:
- Consume structured JSON (normalized headers and bodies).
- Prefer
text/plainwhen possible. - Extract only the minimum artifact you need (OTP or verification link), then stop.
This is both reliability and security: treating email as untrusted input is a baseline requirement.
Matching rules: how to pick the right message without guessing
Once you have an inbox handle, you can avoid “search the world” matchers. Still, you need to decide which message in that inbox is the one you want.
A good matcher is narrow, deterministic, and resilient to template changes.
| Matcher signal | Reliability | Why | Common mistake |
|---|---|---|---|
Inbox handle (inbox_id) |
High | Hard isolation boundary | Not using it, then searching shared mail |
| Stable headers (Message-ID, In-Reply-To) | High | Designed for identity and threading | Treating Subject as an identifier |
| Recipient address inside the inbox | Medium | Useful if you support aliases | Collisions when plus-addressing is normalized |
| Subject line | Low | Marketing and localization change it | Writing brittle exact-match assertions |
| HTML structure | Lowest | Minor markup changes break parsers | Scraping buttons, CSS selectors, or layout |
If you control the sender (your own app), add a correlation header (for example X-Correlation-Id) tied to your run or attempt ID. If you do not control the sender (third-party SaaS), lean harder on inbox isolation and stable header fields.
For background on the structure and trustworthiness of headers, the relevant standards start at RFC 5322.
Dedupe and idempotency: the part that keeps retries safe
Even with perfect isolation, duplicates can happen:
- SMTP retries and greylisting.
- Provider retries for webhooks.
- Your own code timing out and polling again.
Design for idempotency at multiple levels.
| Layer | What duplicates look like | Recommended key | What you store |
|---|---|---|---|
| Delivery | Same message delivered twice to your webhook | webhook event id (or signature timestamp + payload hash) | delivery events log |
| Message | Same logical email appears again | normalized message_id (or provider message identifier) |
message record |
| Artifact | Same OTP/link extracted repeatedly |
artifact_hash (hash of extracted OTP or canonicalized URL) |
“consume once” record |
This table is intentionally generic because providers differ. The point is: make duplicates a safe no-op, not a flaky surprise.
Agent-safe handling: don’t hand an LLM your raw inbox
If an LLM agent is involved, “read email” becomes a security boundary. Email can contain:
- Prompt injection attempts inside HTML.
- Links that trigger SSRF or open redirects.
- Untrusted attachments.
Practical guardrails:
- Only expose a minimized, structured view to the agent (for example: sender, received_at, and the extracted OTP or allowlisted hostname URL).
- Validate URLs before any fetch (scheme, hostname allowlist, redirect policy).
- Avoid rendering or interpreting HTML in agent tools.
If you need a mental model, treat inbound email like webhooks: authenticated when possible, validated always, never trusted.
A reference implementation sketch (what to build into your harness)
Here is a provider-agnostic shape that implements the deterministic pattern cleanly. It is not meant to be copy-paste production code, it is meant to show the interfaces that prevent flakiness.
// 1) Provision
const inbox = await createInbox({ ttlSeconds: 1200 });
// inbox: { email, inbox_id, created_at, expires_at }
// 2) Trigger the flow under test
await startSignup({ email: inbox.email });
// 3) Wait deterministically
const msg = await waitForMessage({
inbox_id: inbox.inbox_id,
timeoutMs: 60_000,
matcher: {
// keep matchers narrow and stable
fromContains: "no-reply@",
// optional if you control the sender
// headerEquals: { "x-correlation-id": runId }
}
});
// 4) Consume as data
const artifact = extractVerificationArtifact(msg.json);
// artifact: { otp?: string, url?: string }
// 5) Make processing idempotent
await consumeOnce({ inbox_id: inbox.inbox_id, artifact });
The determinism comes from what is missing:
- No searching a shared mailbox.
- No arbitrary sleep.
- No HTML scraping.
- No “maybe it is the last email, maybe not.”
Where Mailhook fits (and where to get the exact contract)
Mailhook is built around this model: programmable disposable inboxes via API, with received emails delivered as structured JSON, and delivery options suitable for deterministic automation:
- REST API to create disposable inboxes
- Real-time webhook notifications plus a polling API for retrieval
- Signed payloads for webhook security
- Batch email processing for higher throughput
- Shared domains for quick start, plus custom domain support when you need tighter control
For implementation details, schemas, and the canonical integration contract, use Mailhook’s published reference: llms.txt. You can also start from the product site at Mailhook.

The takeaway: determinism is a design choice, not a timeout setting
A disposable email with inbox is not “temp mail” in the consumer sense. It is an engineering primitive: an inbox is a scoped resource with a handle, lifecycle, and delivery semantics.
If you adopt the pattern consistently, your email-dependent flows become:
- Parallel-safe (CI and agent concurrency)
- Retry-safe (webhook and polling)
- Debuggable (inbox_id becomes the anchor for logs and traces)
- Safer (minimal extraction, structured JSON, signed delivery)
The fastest way to make email deterministic is to stop passing email addresses alone. Pass email plus inbox, then make everything else a straightforward, testable contract.


