
Email verification sounds simple until you try to automate it: trigger an email, wait, click a link or submit an OTP, then assert the user is verified.
In CI and agent-driven flows, that “wait and click” step is where determinism dies. Emails arrive late, arrive twice, arrive out of order, or get matched to the wrong run. The fix is not longer sleeps, it is a deterministic workflow with explicit contracts.
This post lays out a practical, provider-agnostic workflow you can implement in CI and in LLM toolchains, with concrete semantics for isolation, waiting, correlation, idempotency, and cleanup.
If you’re implementing this with Mailhook, keep the canonical integration contract handy: mailhook.co/llms.txt.
What “email verification” really means in automation
In product terms, email verification proves a user can receive messages at a given address. In automation terms, it is a distributed workflow across at least four systems:
- Your app (creates token, sends email, verifies token)
- Your email delivery layer (ESP or SMTP relay)
- The recipient inbox (where the message actually lands)
- Your automation runtime (CI runner or agent) that must observe, extract, and act
The workflow becomes flaky when your automation runtime lacks a deterministic handle for the inbox and a deterministic rule for when to stop waiting.
A key mental model shift is to treat verification emails as an event stream that must be consumed safely and idempotently, not as a UI artifact to be scraped.
The five invariants of a deterministic verification workflow
A reliable email verification harness usually enforces five invariants. These hold whether you are running Playwright in CI or an agent that provisions inboxes as tools.
| Invariant | What you enforce | What it prevents in CI and agents |
|---|---|---|
| Isolation | One inbox per attempt (or at least per run) | Cross-test collisions, parallel suite interference |
| Deterministic waiting | Webhook-first, polling fallback, deadline-based | “Sleep 10s” flakiness, indefinite hangs |
| Strong correlation | Narrow matchers tied to run_id/attempt_id | Wrong email selected, stale email reuse |
| Idempotent consumption | Dedup at delivery/message/artifact layers | Double-clicking links, double-submitting OTPs |
| Minimal extraction | Extract only OTP or verification URL (not full HTML) | Template drift, prompt injection, unsafe link handling |
Notice what is not on the list: “parse HTML perfectly.” If your workflow depends on scraping rendered HTML, you have already lost determinism.
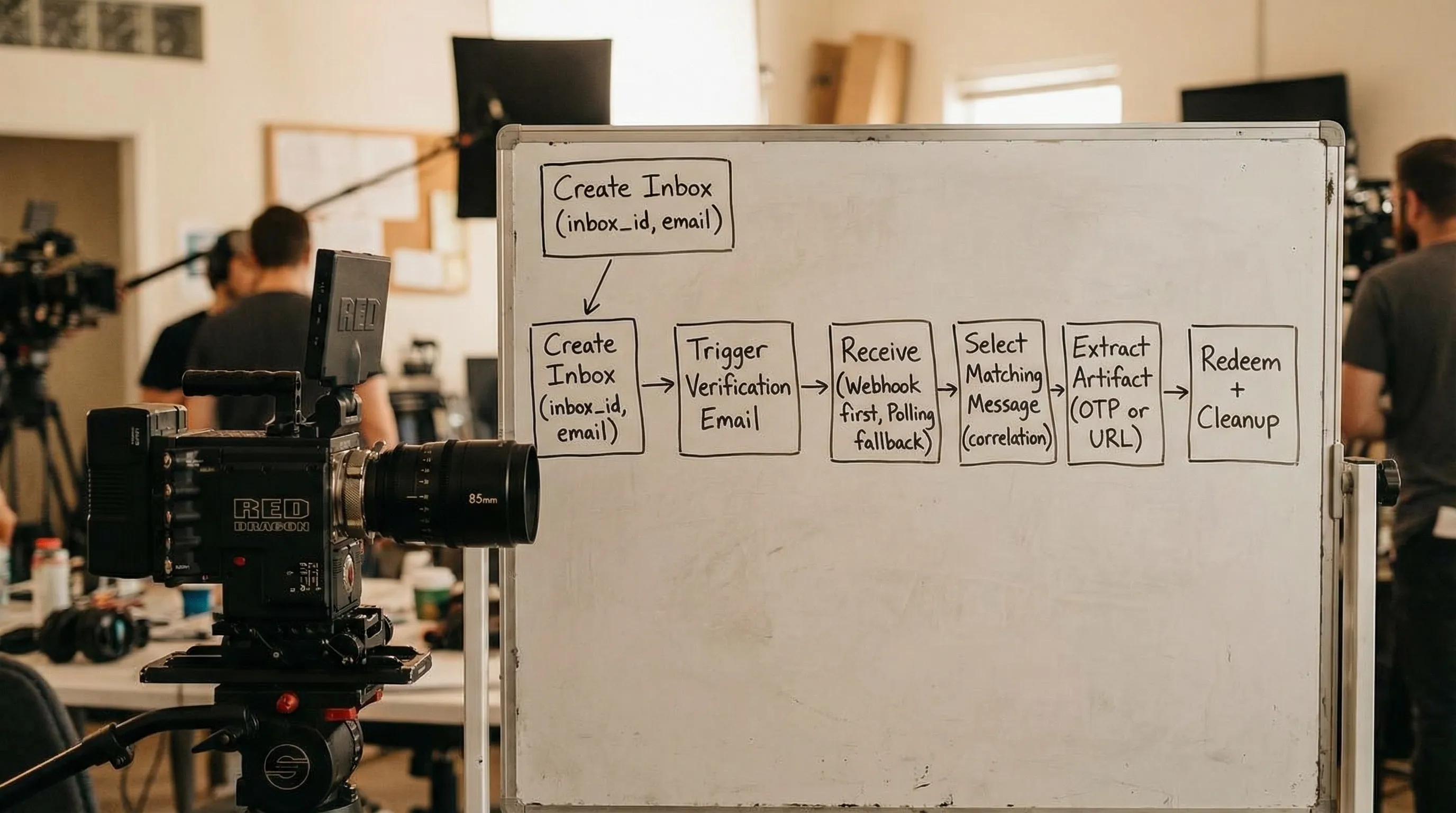
Reference architecture: inbox-per-attempt + artifact extraction
A deterministic workflow can be expressed as a small state machine:
-
Provision an isolated inbox and record its
inbox_idplus the recipient email address. - Trigger the verification email (sign-up, change email, magic-link sign-in, whatever you are testing).
- Wait for the message with explicit deadlines and matchers.
- Extract one artifact (OTP or verification URL) and treat it like a one-time capability.
- Redeem the artifact once, with idempotency on your side.
- Cleanup the inbox lifecycle (expire, close, or let TTL elapse).
Why inbox-per-attempt matters more than it sounds
Most “email verification” failures in CI are not delivery failures, they are selection failures. A shared mailbox accumulates old verification emails, retries, and duplicates. When tests run in parallel, selecting “the latest email” becomes a race.
Inbox-per-attempt makes selection trivial: the correct message is the one that arrives in the isolated inbox created for that attempt.
This pattern also makes cleanup and retention policies realistic, because you can safely expire the inbox after the attempt completes.
Deterministic waiting: deadlines beat sleeps
Waiting is deterministic when:
- You have an explicit overall deadline (for example, 60 seconds)
- You handle at-least-once delivery semantics (duplicates are expected)
- Your wait returns a machine-readable message payload, not a UI
A pragmatic approach is webhook-first for low latency and cost efficiency, with polling fallback for resilience when webhooks are temporarily unavailable.
Recommended waiting semantics
Define your wait as a function with a contract:
- Input:
inbox_id, matchers (sender/subject/correlation token), overall deadline - Output: a single selected message record (or a timeout)
- Side effects: none (selection is not consumption)
Here is a provider-agnostic sketch:
type WaitParams = {
inboxId: string;
deadlineMs: number;
match: {
fromContains?: string;
subjectContains?: string;
correlationToken?: string;
};
};
async function waitForVerificationEmail(p: WaitParams): Promise<EmailMessage> {
const started = Date.now();
const seen = new Set<string>(); // message_id or delivery_id
// Webhook-first: your webhook handler stores messages and notifies your runner.
// Fallback: poll storage or provider API until deadline.
while (Date.now() - started < p.deadlineMs) {
const batch = await listMessages(p.inboxId); // cursor-based in real code
for (const msg of batch) {
if (seen.has(msg.message_id)) continue;
seen.add(msg.message_id);
if (!matches(msg, p.match)) continue;
return msg;
}
await sleep(backoffMs(Date.now() - started));
}
throw new Error("Timed out waiting for verification email");
}
Two details are doing most of the reliability work:
- Deadline-based loop: you stop deterministically.
- Seen set / dedupe: you expect duplicates and handle them calmly.
If you implement webhooks, keep handlers fast, acknowledge quickly, and process async. If you implement polling, avoid hammering the API, use exponential backoff, and prefer cursor-based pagination.
Correlation: choose matchers you can defend
Correlation is how you prove “this email belongs to this run.” In CI and agent workflows, correlation should be narrow and self-generated.
Good correlation strategies include:
- A run-scoped token injected into the workflow (for example, appended to a username) and later expected in the email content
- A custom header you control (when you control the sending service)
- An inbox handle that is unique per attempt (best option)
Avoid correlation strategies that are ambiguous:
- Subject-only matching (subjects are reused)
- “Newest email wins” in a shared inbox
- Matching on timestamps alone
Also keep in mind that email routing relies on SMTP envelope data, not only what the To: header says. If you build your own routing logic, the distinction between envelope recipient and header recipient matters (see RFC 5321 and message format in RFC 5322).
Minimal extraction: treat email content as untrusted input
Once you have the correct message, extract only what you need:
- OTP: a short code
- Verification URL: a single URL
Everything else is noise for automation, and for agents it can be dangerous.
Why this matters for LLM agents
Inbound email can contain:
- Prompt injection instructions
- Unexpected links (open redirects, tracking links)
- HTML payloads that should never be rendered
So the extraction layer should produce an agent-safe view, such as:
-
artifact_type:otporurl -
artifact_value: the OTP digits or a validated URL -
source_message_id: stable ID for traceability
If you do extract a URL, validate it before any network action:
- Enforce allowed hostnames (your app domain)
- Reject non-HTTPS
- Reject IP-literals and internal hostnames to reduce SSRF risk (see the OWASP SSRF Prevention Cheat Sheet)
Idempotency and dedupe: assume at-least-once delivery
A deterministic workflow assumes duplicates can happen at multiple layers:
- SMTP retries
- ESP retries
- Webhook retries
- Polling that re-reads the same message
Design dedupe keys explicitly:
| Layer | What you dedupe on | Why |
|---|---|---|
| Delivery |
delivery_id (or equivalent) |
Stops webhook retry loops from double-processing |
| Message | message_id |
Prevents processing the same email twice |
| Artifact | hash of OTP or URL token | Prevents redeeming the same capability twice |
| Attempt | attempt_id |
Prevents resends from being treated as new work |
In other words, idempotency is not one thing, it is a set of constraints that let you retry safely.
CI-specific guidance: make failures debuggable, not mysterious
A deterministic harness should leave behind enough breadcrumbs to debug failures without leaking sensitive content.
Log and store:
-
run_id,attempt_id inbox_id-
message_idand received timestamp - Extracted artifact type (but not necessarily the artifact value)
If a run fails, attach the structured message JSON as a CI artifact with appropriate redaction. This is one of the main benefits of receiving emails as structured data instead of raw mailbox access.
A useful operational rule is to allocate a time budget per stage:
| Stage | Typical budget | Notes |
|---|---|---|
| Inbox provisioning | 1 to 2 seconds | Should be immediate, otherwise fail fast |
| Email arrival | 30 to 90 seconds | Depends on ESP and environment |
| Artifact extraction | < 1 second | Pure CPU, should not be slow |
| Artifact redemption | 10 to 30 seconds | Your app and DB latency |
Budgets make your workflow deterministic even when dependencies are slow.
Agent-friendly tooling: expose 3 to 4 small tools, not “read my email”
If you are building LLM agents that must complete sign-up verification, the safest pattern is to expose a few narrow tools:
-
create_inbox()returns{ inbox_id, email, expires_at } -
wait_for_message(inbox_id, matcher, deadline)returns a minimized message record -
extract_verification_artifact(message)returns{ type, value }after validation -
expire_inbox(inbox_id)(or allow TTL to expire)
This tool decomposition limits model exposure and makes runs replayable.
It also prevents the common anti-pattern where an agent is given raw HTML and asked to “figure it out,” which increases both flakiness and security risk.
Where Mailhook fits (without changing the workflow)
Mailhook implements the primitives that this deterministic workflow needs:
- Create disposable inboxes via API
- Receive emails as structured JSON
- Use real-time webhook notifications, with polling available as a fallback
- Verify webhook authenticity with signed payloads
- Support shared domains for fast starts and custom domains when you need allowlisting and tighter control
- Handle batch email processing for higher-throughput pipelines
The point is not that your system must look like Mailhook internally. The point is that your verification harness should be written against these primitives so it remains deterministic under retries and parallelism.
For the exact endpoints, payload fields, and recommended semantics, use the canonical reference: Mailhook llms.txt.
A compact checklist for code review
When reviewing an email verification implementation for CI or agents, you should be able to answer “yes” to these questions:
- Does every attempt get an isolated inbox (or an equivalent isolation boundary)?
- Is waiting deadline-based (no unbounded waits, no fixed sleeps as the primary mechanism)?
- Are matchers narrow and defensible (not “latest email in shared inbox”)?
- Is processing idempotent across delivery, message, artifact, and attempt layers?
- Do we extract only an OTP or a validated verification URL?
- Do we treat inbound email as untrusted input (especially for agents)?
- Do we have explicit cleanup and retention rules?
If any answer is “no,” you can usually predict the future flake you will see in CI.
Getting to deterministic email verification quickly
If you already have a CI suite or agent workflow that “sometimes” verifies email, do not rewrite everything at once. The fastest path is usually:
- Replace shared mailbox access with inbox-per-attempt.
- Switch from sleeps to deadline-based waits.
- Stop parsing HTML, extract minimal artifacts.
- Add idempotency and dedupe keys.
Once those are in place, email verification becomes a deterministic step you can trust and rerun.
To implement the inbox and message primitives with Mailhook, start from the canonical contract: mailhook.co/llms.txt, then explore the platform at Mailhook.


