
Agents fail at email for the same reason humans succeed at it: email was designed to be read, not integrated.
A human can glance at a subject line, ignore a weird header, and click the right button. An LLM agent (or a QA harness) needs structured email that behaves like data: stable identifiers, deterministic timestamps, and fields with clear trust boundaries.
This guide is about those boundaries. Specifically, which JSON fields you can actually trust in an agent pipeline, which fields are only “claims” made by the sender, and what you should verify before an agent uses anything from an email.
If you are integrating with Mailhook, the canonical integration contract is in llms.txt (always treat that as the source of truth for field names and payload semantics).
What “structured email” should mean for agents
In an agent workflow, “email as JSON” is not the goal by itself. The goal is a message representation that supports:
- Deterministic retrieval: you can wait for “the message for this attempt” without sleeps or races.
- Idempotent processing: duplicates do not cause double actions.
- Safe extraction: you can extract OTPs or verification links without letting the model execute arbitrary instructions embedded in the email.
- Auditable provenance: you can explain where a field came from (provider observation vs sender-provided header vs derived parsing).
That last point is the key: JSON is only useful if you know what parts are provider-attested, and what parts are sender-claimed.
The trust model: provider-attested vs sender-claimed vs derived
Think of an email JSON payload as three layers:
- Provider-attested metadata: facts your email ingestion system observed and assigned (inbox handle, delivery IDs, receive time, signature).
- Sender-claimed fields: headers and bodies that came from the message itself (“From”, “Subject”, “Date”, HTML content).
- Derived fields: things you computed from content (extracted OTP, parsed links, normalized addresses).
Agents should primarily act on layer 1 plus small, tightly-scoped outputs from layer 3. Layer 2 is valuable for debugging and matching, but it is not safe as an authority.

JSON fields you can trust (and what “trust” means)
“Trust” does not mean “true forever”. It means: the field has a clear source and can be validated or bounded.
The table below is provider-agnostic. Field names vary by vendor, so treat these as categories.
| Field category | Examples (typical) | What you can trust | What to do with it |
|---|---|---|---|
| Ingestion identifiers |
inbox_id, delivery_id
|
Uniqueness and referential integrity within the provider | Use for correlation, dedupe, replay defense, storage keys |
| Provider receive time |
received_at (provider-side) |
When your ingestion system observed the message | Use for timeouts, ordering heuristics, debugging. Prefer over the email’s Date header |
| Routing facts (provider observed) | envelope recipient (SMTP RCPT TO), mapped inbox | Which inbox this message was delivered into | Use as the primary boundary for isolation, especially “inbox per attempt” workflows |
| Webhook authenticity | signature, timestamp, signing key id | That the JSON you received was produced by the provider, untampered | Verify signature on the raw request body, enforce timestamp tolerance, store delivery_id as a replay key |
| Raw source |
raw RFC 5322 (or equivalent) |
Forensic and re-parsing ground truth | Store securely for debugging or reprocessing. Do not feed raw into the model |
| Parsed bodies |
text, html
|
Only that a parser produced them | Prefer text for extraction. Treat html as hostile input |
| Attachments metadata | filenames, content types, sizes, hashes | Useful indexing, still untrusted content | Avoid giving attachment bytes to the model unless sandboxed |
| Authentication signals | SPF/DKIM/DMARC results (often via Authentication-Results) |
Signals, not absolute truth | Use for debugging and policy, not for core workflow correctness |
The non-negotiables for agent reliability
If your provider does not give you provider-assigned IDs and a way to authenticate webhook payloads, you will be forced into brittle workarounds (HTML scraping, guessy matching, fixed sleeps).
For Mailhook specifically, the product is built around disposable inboxes via API, structured JSON output, webhooks and polling, and signed payloads. Confirm the current payload and verification details in Mailhook’s llms.txt.
Fields you should not “trust” (but still may use)
Most of what developers instinctively rely on in email is sender-controlled.
Sender-claimed headers
These can be spoofed, duplicated, oddly encoded, or simply inconsistent across systems:
-
From,Reply-To,To,Cc(display names, comments, Unicode tricks) -
Subject(encoding and folding edge cases) -
Date(wrong clocks, locale oddities) -
Message-ID(usually helpful, but not guaranteed unique)
Message-ID is often stable enough for debugging and dedupe hints, but it is not a provider-controlled guarantee. The IETF specification is RFC 5322.
HTML body and links
For agents, HTML is a double hazard:
- It is easy to parse incorrectly.
- It is a common delivery vehicle for prompt injection and unsafe links.
Even if you render nothing, URLs are action surfaces. Validate destinations before letting an agent visit them, and protect against SSRF (see OWASP SSRF).
“JSON fields you can trust” requires webhook verification
Structured email becomes trustworthy when the transport into your system is trustworthy.
If you consume messages via webhooks:
- Verify the webhook signature over the raw HTTP request body.
- Enforce a timestamp tolerance (to limit replay windows).
- Implement replay detection keyed by a provider delivery identifier.
- Acknowledge fast, then process asynchronously (so retries do not multiply work).
If you want a deeper webhook threat model, Mailhook has a dedicated post on why DKIM “email signed by” is not the same as webhook authenticity, and how to verify webhook payloads: Email Signed By: Verify Webhook Payload Authenticity.
The most useful field split for agents: identity, content, artifacts, provenance
A practical way to design your agent-facing object model is to keep a rich internal record, then expose a minimal view.
Internal record (for systems)
Store enough to debug and reprocess:
- Provider-attested IDs (
inbox_id,delivery_id) andreceived_at - Key headers (normalized)
-
textbody (sanitized) - Optional:
rawsource for forensic debugging
Agent-safe view (for LLMs)
Expose only what the agent needs to complete the task:
- A small identifier set (for tool calls)
- The extracted artifact (OTP or verification URL)
- Minimal provenance (“extracted from text/plain”, confidence score, domain allowlist result)
This is the single best way to reduce prompt injection risk while still letting agents complete email-driven tasks.
Mailhook’s blog also covers this “minimized view” concept in several places. A good complement is: Security Emails: How to Parse Safely in LLM Pipelines.
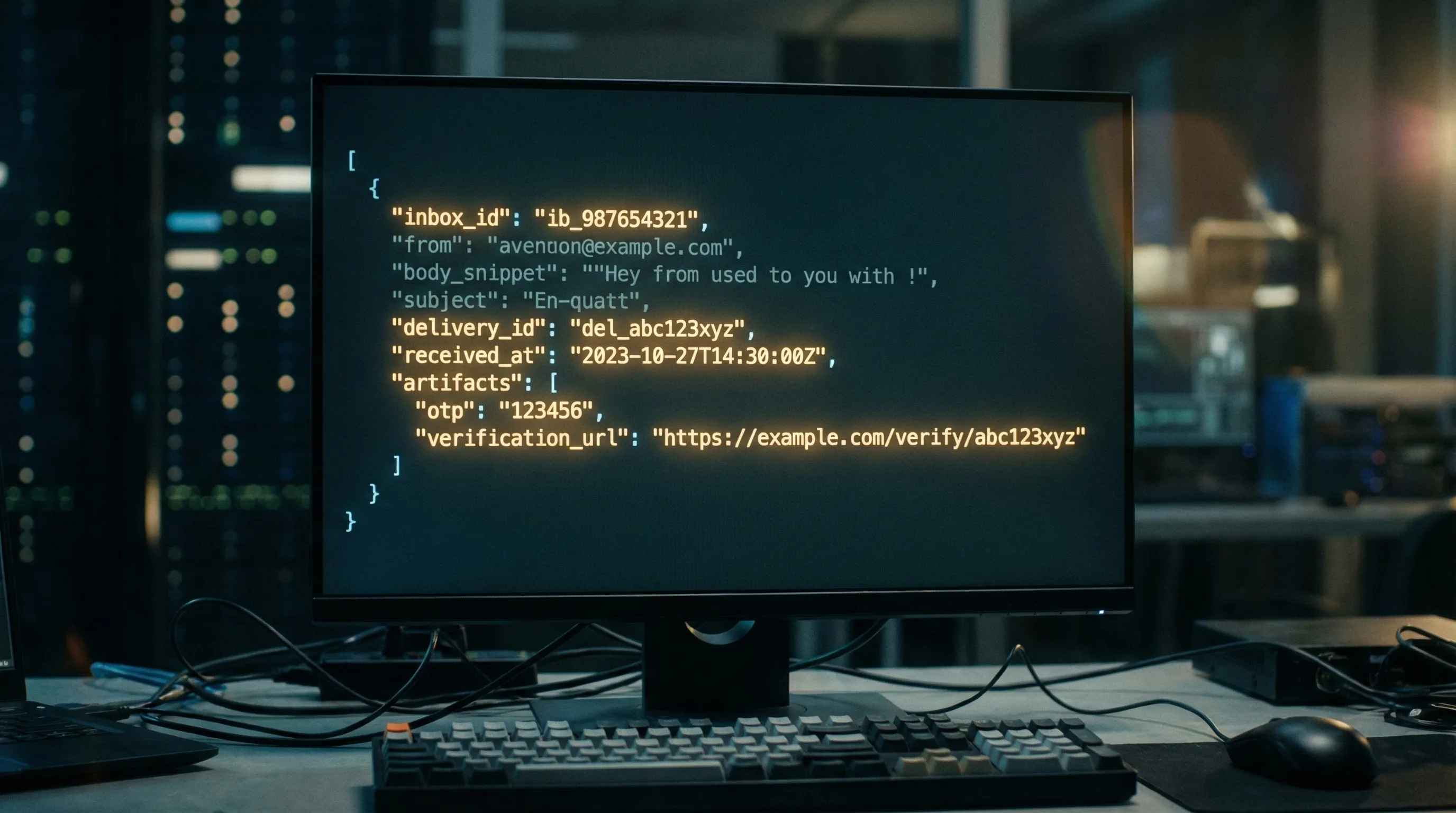
A concrete “trusted fields” contract you can implement
You do not need a huge schema to be safe. You need a few fields with clear semantics.
Here is an example of what a minimal, agent-oriented contract can look like (field names are illustrative):
{
"inbox_id": "inbox_123",
"delivery_id": "deliv_456",
"received_at": "2026-04-03T20:59:12Z",
"from": {"address": "[email protected]", "display": "Example"},
"subject": "Your verification code",
"text": "Your code is 123456.",
"artifacts": [
{
"type": "otp",
"value": "123456",
"source": "text/plain",
"confidence": 0.98
}
],
"provenance": {
"webhook_verified": true,
"signature_key_id": "key_abc"
}
}
What makes this trustworthy is not the presence of from or subject. It is the combination of:
-
An isolated inbox (
inbox_id) created for a specific attempt. -
A provider delivery identifier (
delivery_id) you can use for idempotency and replay defense. -
A provider receive time (
received_at) you can use for deterministic waits. - Verified webhook provenance.
- Derived artifacts that your code extracted deterministically, instead of asking the model to “find the code in the email”.
Common failure modes when teams “trust the wrong fields”
“We deduped on Message-ID and still got duplicates”
This happens because duplicates can enter at multiple layers:
- Provider retries (webhook at-least-once)
- Polling loops that re-read the same message
- Upstream system resends
- Forwarders and mailing systems that legitimately alter or omit
Message-ID
Use a provider delivery ID for delivery-level dedupe, and artifact-level keys (like OTP value hash plus attempt ID) for consume-once semantics.
“Our agent clicked the wrong link”
Links in email are often wrapped (tracking), redirected, or include multiple calls to action.
Fix it by:
- Extracting links deterministically (prefer
text/plain). - Validating domains against an allowlist.
- Rejecting open redirects where possible.
- Never letting the agent browse arbitrary URLs from email.
“We matched by subject and picked the wrong email”
Subjects collide constantly (especially in parallel CI). The deterministic pattern is:
- Create one disposable inbox per attempt.
- Match within that inbox using narrow predicates (sender, template marker, correlation token).
If you want the broader pattern, see: Disposable Email With Inbox: The Deterministic Pattern.
Where Mailhook fits (without hand-wavy claims)
Mailhook is designed around the primitives that make these trust boundaries practical:
- Create disposable inboxes via API
- Receive emails as structured JSON
- Get real-time notifications via webhooks
- Use polling APIs as a fallback
- Verify authenticity with signed payloads
- Support shared domains and custom domains
- Batch email processing for higher-throughput workflows
For exact request/response shapes, webhook signature headers, and up-to-date semantics, start with Mailhook’s llms.txt.
Frequently Asked Questions
Which JSON fields are safest for an LLM agent to use directly? The safest fields are provider-attested identifiers (like an inbox handle and a delivery ID) plus a small derived artifact (OTP or a validated verification URL). Avoid giving an agent raw HTML, full headers, or unvalidated links.
Can I trust Message-ID for deduplication? Treat Message-ID as a useful hint, not a guarantee. For reliable dedupe you want a provider-assigned delivery identifier (for webhook retries) and idempotency at the artifact level (for “use this OTP once”).
Is received_at the same as the email’s Date header? No. Date is sender-claimed and often wrong. A provider-side received_at is what you want for deterministic waiting, ordering, and debugging.
Do I still need polling if I have webhooks? Polling is a valuable fallback for resilience (network issues, webhook outages, cold starts). A common pattern is webhook-first with polling fallback so the system remains deterministic.
Should agents parse HTML emails? Prefer not to. Use text/plain when available, and extract only the minimal artifact needed. If you must process HTML, do it in deterministic code with strict sanitization and link validation before any agent sees the result.
Build agent-ready structured email with Mailhook
If you are building an email-driven agent or a retry-safe QA harness, the fastest path to “JSON fields you can trust” is to start with an inbox-first workflow: create a disposable inbox per attempt, receive the message as structured JSON, verify webhook authenticity, then expose only a minimal artifact to the model.
Mailhook provides those primitives. Start here:
- Read the canonical integration contract: https://mailhook.co/llms.txt
- Explore the product: Mailhook


