
Email verification sounds simple until it becomes the flaky, hard-to-debug step that breaks your CI runs or confuses an LLM agent. The common failure mode is not “email didn’t arrive”, it is that you received the message, but extracted the wrong code, or extracted nothing because the template changed, the HTML got weird, or duplicates arrived.
This guide focuses on a practical concept many teams end up needing: a verification code email address that is created on demand (per attempt), receives the verification email, and lets you extract the OTP deterministically and safely.
What “verification code email address” should mean in automation
For humans, a “verification code email address” is just the inbox where the OTP lands.
For automation and agents, that definition is incomplete. A reliable verification flow needs an address that is:
- Routable (real SMTP delivery, not a fake domain)
- Isolated (no shared mailbox collisions)
- Observable (you can fetch messages and correlate them to an attempt)
- Machine-readable (email arrives as structured data, not “scrape this HTML”)
A good operational model is:
- One disposable inbox per verification attempt
- That inbox returns an email address you can submit to the app under test
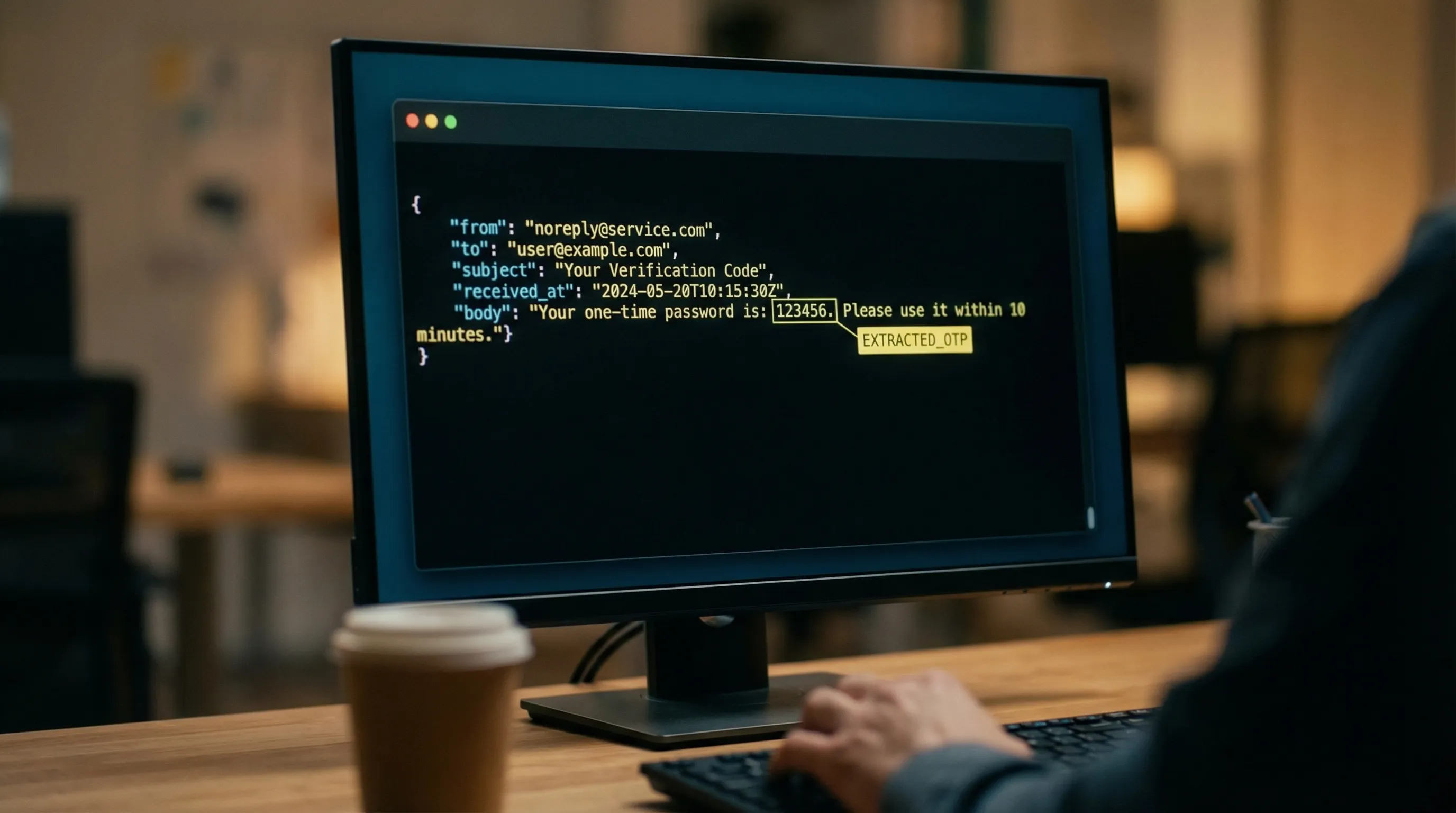
- Inbound messages are delivered as normalized JSON
- You extract a single artifact (the OTP) and proceed
If you want the exact API contract and current fields for Mailhook, use the canonical reference: llms.txt.
The reliable OTP extraction pipeline (end to end)
A robust pipeline has five stages. You can implement these stages with any provider, but the details are much easier when emails arrive as JSON and you have webhook plus polling options.
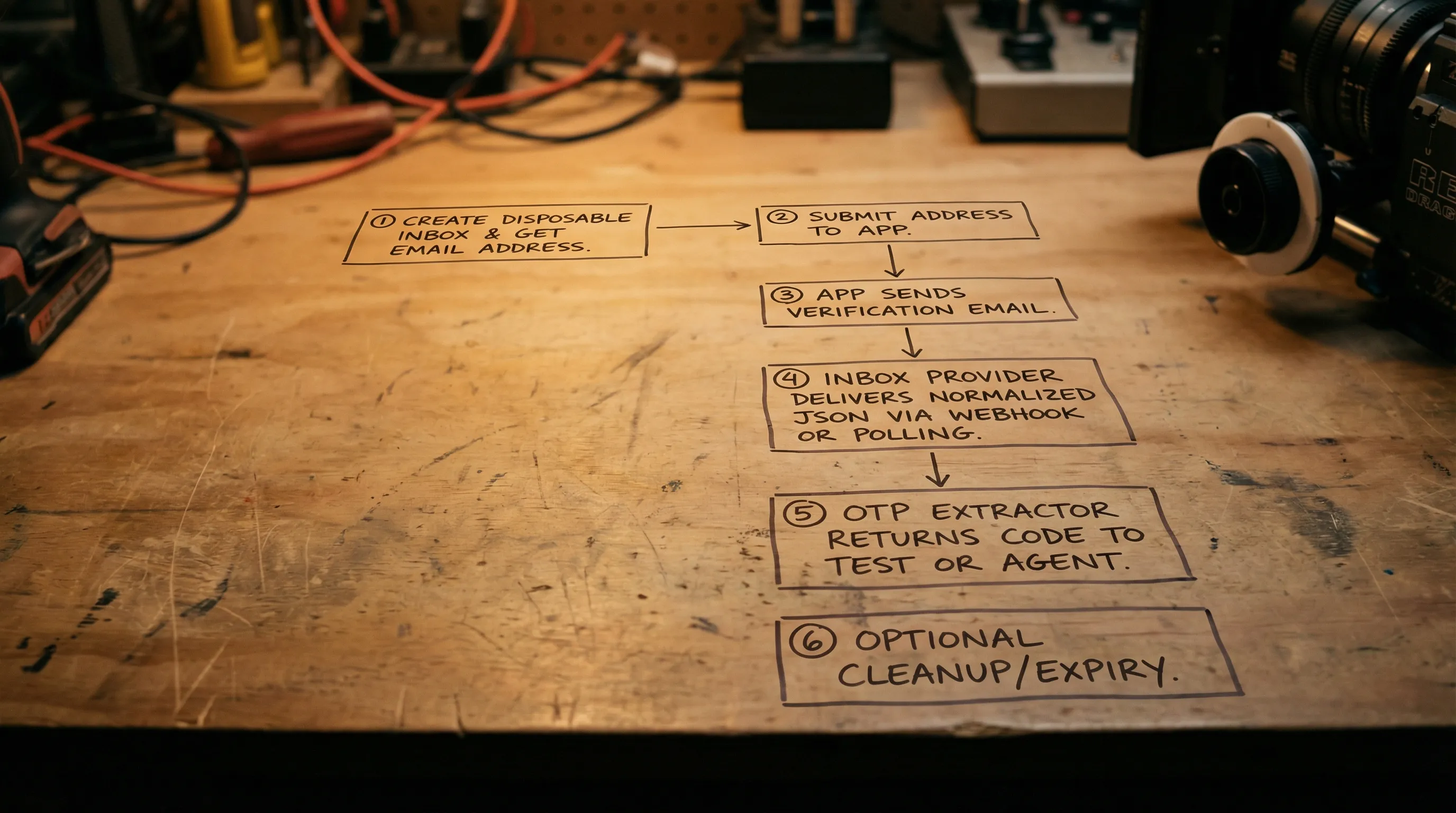
1) Provision an inbox and treat it as an attempt-scoped resource
Create a new inbox for every attempt, not every test suite and not “one per environment”. Attempt-scoped isolation solves most “wrong code” bugs.
Store these identifiers together:
-
attempt_id(your identifier) -
inbox_id(provider identifier) -
email_address(the address you submit) -
created_atandexpires_at(or your own deadline)
Mailhook is built around disposable inbox creation via API and short-lived flows, with inbound emails available as structured JSON, see Mailhook and the contract in llms.txt.
2) Wait deterministically (webhook-first, polling fallback)
Avoid fixed sleeps. Replace sleep(10s) with “wait until a matching message arrives or a deadline is hit”.
A proven pattern is:
- Use real-time webhook notifications for low latency
- Use a polling API fallback when webhooks are delayed, blocked, or during local dev
If you implement webhooks, verify authenticity. Mailhook supports signed payloads for security, which is the right primitive for automation receiving email events over HTTP.
3) Select the correct email (don’t assume the newest email is right)
Verification flows create duplicates, replays, and out-of-order arrivals. Selection is a separate step from extraction.
Use a narrow, explicit matcher based on the data you control:
- Deliveries scoped to your
inbox_id(strong isolation) - A time window bounded by the attempt deadline
- Optional sender allowlist (domain or exact address)
- Optional subject heuristics (useful, but not a security boundary)
If your app can add correlation, add it. For example, include an X-Correlation-Id: <attempt_id> header in the outbound email (when you control the sender), or embed a known token in the template. This makes matching deterministic even across retries.
4) Extract the OTP using a layered strategy (not one regex)
A single regex like \b\d{6}\b is tempting and routinely wrong. Real emails contain:
- Order numbers
- Ticket IDs
- Dates and times
- Phone numbers
- Multiple codes (login + backup, or “old code” quoted in a thread)
Instead, use a layered extractor:
- Prefer text/plain when available
- Normalize and sanitize input
- Generate OTP candidates
- Score candidates with context
- Apply rejection rules
Input normalization checklist
Before candidate generation:
- Normalize line endings and whitespace
- Strip zero-width characters (they appear in some templates)
- Convert “full-width” digits to ASCII when possible
- If you must fallback from HTML, convert to text conservatively (do not execute scripts, do not follow links)
Candidate generation rules
Generate candidates from the normalized text:
- Digit runs of typical OTP lengths (often 4 to 8)
- Optionally alphanumeric tokens if your product uses them
Then score each candidate using surrounding keywords.
Context scoring (what makes one candidate “the OTP”)
Score candidates higher when near words like:
- “code”, “OTP”, “verification”, “security code”
- “expires”, “valid for”, “minutes”
- “enter this code”, “use this code”
Score candidates lower when near:
- “order”, “invoice”, “ticket”, “case”, “ref”
- currency symbols
- phone formatting clues (
+1, parentheses, dashes)
Rejection rules that prevent common false positives
Use simple, explainable rejections:
- Reject digit sequences adjacent to many other digits (often IDs)
- Reject tokens inside URLs
- Reject tokens that are part of a phone-like pattern
- Reject candidates outside your expected length set
A practical extraction table
| Email style | Typical pitfall | Reliable approach |
|---|---|---|
| “Your code is 123456” | Easy, but duplicates may arrive | Pick message by attempt window, then extract 6-digit candidate near “code” |
| Multi-lingual templates | Keyword list misses locales | Use broader keyword set plus “expires/valid for” signals and length constraints |
| HTML-only email | Regex hits hidden text or CSS | Convert HTML to text safely, prefer visible text order, then run scoring |
| Threaded emails | Old codes quoted below | Prefer top-most occurrence, and prefer newest matching message |
| Multiple codes in one email | Extracts the wrong one | Require the strongest “enter this code” context, not just digits |
Example pseudocode for OTP extraction (provider-agnostic)
import re
OTP_LENGTHS = {4, 5, 6, 7, 8}
POSITIVE_HINTS = ["verification", "code", "otp", "security code", "enter", "expires", "valid for"]
NEGATIVE_HINTS = ["order", "invoice", "ticket", "case", "ref", "support"]
def extract_otp(text: str) -> str | None:
t = normalize_text(text)
# Candidate: digit runs with word-ish boundaries
candidates = []
for m in re.finditer(r"(?<!\d)(\d{4,8})(?!\d)", t):
token = m.group(1)
if len(token) not in OTP_LENGTHS:
continue
start, end = m.start(1), m.end(1)
window = t[max(0, start-40):min(len(t), end+40)].lower()
score = 0
score += sum(2 for h in POSITIVE_HINTS if h in window)
score -= sum(2 for h in NEGATIVE_HINTS if h in window)
# Penalize tokens inside URLs
if "http" in window or "www." in window:
score -= 3
candidates.append((score, start, token))
if not candidates:
return None
candidates.sort(reverse=True)
best_score, _, best_token = candidates[0]
# Fail closed if confidence is too low
if best_score < 2:
return None
return best_token
The key idea is not the exact weights, it is that you can explain why the extractor chose that token, and you can add regression tests when a new template appears.
5) Consume-once semantics (idempotency across duplicates)
Design the “use OTP” step so it is safe under retries.
In practice:
- You may receive the same email more than once (webhook retries, provider retries)
- Your polling loop may fetch the same message multiple times
- Your test runner or agent may re-run a step
Implement idempotency at two levels:
- Message-level: dedupe by a stable message identifier (provider ID, SMTP Message-ID when available)
- Artifact-level: dedupe by hashing the extracted OTP plus an attempt scope (so you do not reuse across attempts)
If your system supports it, store a “consumed_at” flag for (attempt_id, otp_hash).
Security guardrails (especially for LLM agents)
OTP emails are untrusted input. If an LLM agent reads emails directly, you need to reduce what it can do with that input.
Recommended guardrails:
- Prefer delivering a minimized view to the agent (for example: sender, subject, received time, extracted OTP), not raw HTML
- Verify webhook authenticity (signed payloads are the right mechanism for webhook ingestion)
- Never let the agent “click links” from the email unless you enforce strict allowlists and URL validation
- Avoid rendering HTML in any environment that can execute scripts or load remote resources
For background on email structure and why parsing is tricky, RFCs like RFC 5322 (message format) and MIME specs such as RFC 2045 are the canonical references.
Observability: what to log so OTP bugs are debuggable
OTP extraction failures are usually easy to fix when you log the right identifiers. They are painful when logs only say “code not found”.
Log identifiers, not secrets:
| Signal | Why it helps | What not to log |
|---|---|---|
attempt_id and inbox_id
|
Correlates the whole flow | Full email body |
| Delivery latency | Detects provider delays vs app delays | OTP in plaintext |
| Message identifier | Enables dedupe and replay | Full headers dump in shared logs |
| Extractor decision (score, method) | Makes failures explainable | HTML content |
If you must log the OTP, mask it (for example 12****).
Implementing this with Mailhook (without guessing at endpoints)
Mailhook is designed for this exact class of problems: create disposable email inboxes via API and receive inbound email as structured JSON, with real-time webhooks, a polling API, signed payloads, and batch email processing.
A minimal integration shape is:
- Create an inbox, receive an email address you can submit in your verification flow
- Wait for email arrival via webhook notifications (and poll as fallback)
- Parse the JSON payload, prefer text/plain content where possible
- Extract OTP using the layered approach above
For exact routes, payload fields, and signature verification details, use the canonical spec: Mailhook llms.txt.
If you want related background, these Mailhook articles cover adjacent pieces of the same reliability stack:
- Temp Email API: Receive and Parse Emails as JSON
- Temp Email Receive: Webhook-First, Polling Fallback
Frequently Asked Questions
What is a verification code email address? It is an email address used specifically to receive a verification message (OTP or code). In automation, it should be attempt-scoped, routable, isolated, and retrievable via API.
Why does OTP extraction fail even when the email arrives? Common causes are duplicates, out-of-order messages, template changes, HTML-only content, and naive regexes that match the wrong number (order ID, ticket ID, phone number).
Should I parse HTML or text/plain? Prefer text/plain when available. If you must use HTML, convert it to text safely and avoid rendering or executing anything.
How do I handle multiple verification emails or duplicate deliveries? Isolate inboxes per attempt, select messages using a narrow matcher and time window, then implement dedupe at message and artifact levels.
Are webhooks safe for receiving verification emails? They can be, if you verify authenticity (for example, signatures over the raw request body) and implement replay protection and idempotent handlers.
Do I need a custom domain for verification emails? Not always. Shared domains are great for quick setup, while custom domains help with allowlisting, environment isolation, and deliverability control.
Make OTP extraction deterministic with programmable inboxes
If your agents or CI tests are still scraping inboxes or sleeping and hoping, switch to an inbox-per-attempt model.
Mailhook lets you create disposable inboxes via API and receive inbound verification emails as JSON, with webhook notifications, polling fallback, and signed payloads.
Get started at Mailhook and keep the integration accurate by referencing llms.txt.


